

The Virtual Cell Revolution
Our latest deep dive on how virtual cells could revolutionize drug testing.


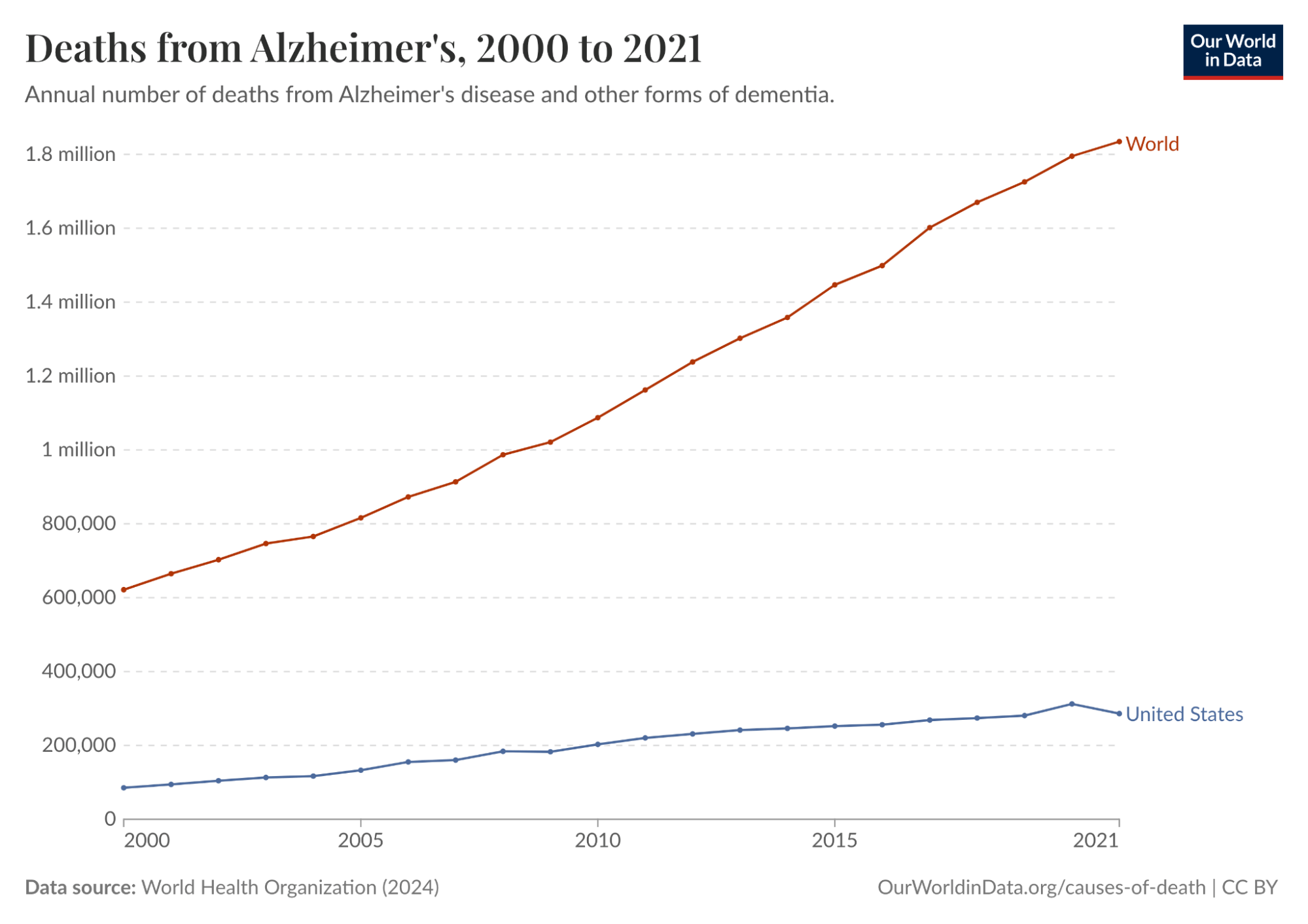
Alzheimer’s disease is one of the deadliest and costliest diseases on Earth. It kills hundreds of thousands of Americans every year, afflicts an estimated 11% of all Americans 65 and older in 2026 (roughly 7.4 million people), and costs Americans $340 billion annually. In 2024, it was the fifth-leading cause of death among people over 65. And it’s only getting worse. Total deaths from Alzheimer’s in the US increased more than 3x from 2000 to 2021. Globally, annual deaths from Alzheimer’s have grown from 621.7K in 2000 to over 1.8 million in 2021.
Despite all this, there has been no meaningful progress towards a cure, even though enormous resources have gone into Alzheimer’s R&D. There was an estimated $42.5 billion of private investment in Alzheimer’s R&D between 1995 and 2021 alone, but much of this investment was a complete waste. One study conducted in 2014 found a 99.6% failure rate in Alzheimer’s drug clinical trials conducted between 2002 and 2012. As a result, the FDA did not approve a single new Alzheimer’s treatment in the 18 years between 2003 and 2021.
A big reason for the wastefulness of Alzheimer’s research was that much of it relied on an imperfect proxy as its starting principle. For over two decades, the leading hypothesis for Alzheimer’s was the “amyloid cascade”: the idea that toxic protein clumps called amyloid-beta plaques were the primary driver of the disease. Almost every major pharmaceutical company based its Alzheimer’s drug development on this idea.
The problem was that the mouse models used to validate it were engineered to develop amyloid plaques, but they never actually had Alzheimer’s. They lacked the tau protein tangles, the widespread neuronal death, and the microglial dysfunction that research suggests is central to how the disease progresses in humans. When drugs cleared plaques in mice and appeared to restore cognition, they succeeded in treating the model. But when those drugs entered human trials, despite successfully clearing plaques in patients as predicted, they had little to no effect on cognitive decline.
Ultimately, Alzheimer’s drugs had such a high failure rate, both because they went after the wrong target and because they used mouse models as an inaccurate proxy to test a treatment meant for human beings. Mouse models don’t develop Alzheimer’s the way humans do, although they were convincing enough to sustain a $42.5 billion research program for 25 years at a 99.6% failure rate. In this way, Alzheimer’s exemplifies the underlying problem with the status quo in drug development: we rely on imperfect biological proxies until we get human trial data, limiting the speed and efficacy of drug development at enormous cost in time, money, and lives.
Relying on such proxies affects all three stages of drug development. The first stage is targeting: identifying which molecule in a cell is causally responsible for a disease. The second is treatment: designing a drug that reaches that target without causing unacceptable side effects elsewhere. The third is trials: testing the drug in the right patients, at the right dose, measuring the right outcomes. Failure at any of these stages can lead to years of wasted work and enormous financial loss.
The inherent inefficiencies of this paradigm have led to a phenomenon known as Eroom’s Law, which holds that drug discovery has become exponentially slower and more expensive since the 1980s. Despite dramatic advances in molecular biology, genomics, and screening technologies, the cost of bringing a single new drug to market has risen to over $2 billion, while 90% of drugs that enter clinical trials fail.
Clearly, something needs to change. A new paradigm is needed. The most promising candidate for that shift is the virtual cell: a computational model trained on human biological data that simulates how a cell responds to a drug or genetic change. Instead of inferring human biology from a mouse or other animal’s drug response, a virtual cell learns the rules of human cellular behavior directly from human data, including which genes are active, how they regulate one another, and how that network shifts under disease or intervention.
In the context of Alzheimer’s, a well-trained virtual cell might have revealed earlier that amyloid plaques were a symptom of a deeper dysfunction, driven partly by the brain’s immune cells becoming locked in a self-reinforcing inflammatory state, rather than the root cause. It would not have been a guarantee, but it could have narrowed the target list faster and flagged the mismatch between mouse and human biology sooner.
This essay is intended to paint a picture of virtual cells and their potential to help finally overthrow the long stagnation in drug development described by Eroom’s Law. It begins by diagnosing why drug development is so slow and costly, tracing the history of biological proxies from the first animal testing requirements in 1938 to the organ-on-chip systems the FDA is validating today. It then describes what virtual cells are and why now is the right moment to build them. From there, it surveys the diseases for which virtual cells are most likely to make a difference. Finally, it lays out the key companies in the virtual cell landscape and describes how virtual cells may usher in a new era for drug development.
Of the many promising potential applications of virtual cells, one can already be put in practice: using virtual cells to understand how the same diseases present differently across a patient population, i.e. for patient stratification. In the future, virtual cells may well become the foundation of a faster, more accurate, and lower-cost testing regime, and thereby bring about a new renaissance in drug discovery. However, existing testing techniques, such as animal testing, will be unlikely to disappear entirely, as they will likely continue to be useful supplements to virtual cells even if their full potential is realized.
Why Drug Development Is Broken
Eroom’s Law is Moore’s Law spelled backward because it represents a phenomenon that is the mirror image of Moore’s Law, a decades-long trend in which computing power became both exponentially more powerful and cheaper at the same time. By contrast, over the past 70 years, the number of new drugs approved per dollar of R&D spending has roughly halved every decade.

The advent of AI pits Moore’s Law against Eroom’s Law. The virtual cell is an application of AI in biology that has the potential to translate progress in computing into advances in medical treatment, and thereby fulfill the lofty predictions of frontier AI labs. It bridges the gap between the world of AI and the world of cells. But to understand the potential of virtual cells going forward, it is important to understand the limitations of the drug discovery process as it functions today. As mentioned earlier, there are three broad reasons why 90% of drugs fail to reach patients today; three possible points of failure in the drug discovery pipeline: targeting, treatment, and trials.
Failure Mode 1: Targeting
To cure a disease, you first need to know what’s causing it. There are typically many molecules in a cell, such as DNA, RNA, and proteins, that could cause disease. A single human cell contains an estimated several billion protein molecules, and identifying the right target for a drug is difficult. The Alzheimer’s story illustrates what happens when the wrong target is chosen: billions and decades spent pursuing amyloid plaques, a target that turned out to be a symptom rather than a cause.
But the amyloid case is not unique. A single diseased cell can contain hundreds of plausible molecular targets, and without a way to systematically narrow that list, picking the right one is largely a matter of trial and error. This is almost certainly one of the forces compounding Eroom’s Law: the more potential targets we discover through advances in genomics, the harder it gets to identify the right one.
Failure Mode 2: Treatment
Even when the right target is chosen, a drug can still fail if it can’t reach that target effectively, or if it causes unacceptable side effects in the process. Pfizer’s torcetrapib is a stark example. The drug was designed to raise HDL, or “good” cholesterol, as a treatment for cardiovascular disease, and it worked: HDL levels rose by 72% in trials. Pfizer’s CEO called it “one of the most important compounds of our generation.”
Three days later, Pfizer halted its Phase 3 trial after the drug showed a 58% higher rate of death compared to placebo. It turned out the drug was stimulating hormone secretion from the adrenal glands, a side effect entirely unrelated to its intended target. Pfizer had invested approximately $800 million in the drug, and its stock fell 10% on the day the trial was halted, wiping out $21 billion in market cap and clearly illustrating how costly failures can be when treatments have unintended effects that are nearly impossible to predict.
Failure Mode 3: Trials
Even with the right target and a drug that reaches it safely, a clinical trial can still fail if it enrolls the wrong patients. AstraZeneca’s MYSTIC trial in 2017 is one example. The trial tested a combination of two immunotherapy drugs against non-small cell lung cancer in an effort to compete with Merck’s Keytruda. By 2017, the field had already established that response to these drugs depended heavily on the level of PD-L1 expression in a patient’s tumor.
Merck had set its patient selection threshold at 50% PD-L1 expression, a cutoff that enriched its trial for likely responders and helped make Keytruda the world’s best-selling drug. AstraZeneca, by contrast, set its threshold at 25%, diluting its trial population with patients unlikely to respond. The MYSTIC trial failed its primary endpoint, and AstraZeneca’s stock fell 16% in a single day, wiping out about $10 billion in market cap. The difference between thresholds of 25% and 50% costs a decade of progress for patients and billions for shareholders, exemplifying the broader principle that clinical trial design is critically important to drug development but very difficult to do based on the educated guesses that drug developers must rely on based on our limited understanding of the underlying biology.
Our Limited Understanding of Biology
These three failure modes share a common root. In each case, the underlying problem is an insufficient understanding of human biology at the cellular level. The wrong target was chosen in Alzheimer’s because mouse models gave a misleading signal. Torcetrapib’s fatal side effect went undetected because no preclinical model predicted what the drug would do to human adrenal hormone secretion. AstraZeneca set the wrong patient-selection threshold because PD-L1 expression is a crude proxy for the far more complex cellular dynamics that determine whether a patient’s immune system will respond.
In each case, an imperfect biological proxy produced a plausible but ultimately false signal, hundreds of millions of dollars and years of work followed, and human trial data eventually made it clear that the wrong path was being pursued. Understanding why this keeps happening requires a closer look at the tools we use to model human biology and why they’re so limited.
The above is an excerpt from our new deep dive on virtual cells and the future of drug testing. See the full report here.
This was a pleasure to help with!